Introduction
It is always a good idea to revisit best practices for extracting information from web pages. Traditional web scraping tools and techniques often involve using libraries like BeautifulSoup and Scrapy to parse HTML and extract data, but they can struggle with dynamic content rendered by JavaScript. A classic example often involves news articles, so I will use that on this article.
Important: Check if the website allows you to scrape it before using this info (normally you can check the robots.txt) in any production system. This article is only meant to be for learning purposes
Our goal
This article assumes you already have a list of URLS you want to process. In this example, the goal is to leverage LLMs to replace custom parsing and extraction:
- Read article content (URL)
- Extract “some” information from it
- More advanced processing, such as Named Entity Recognition (NER) to extract certain entities mentioned in the article.
Note: Using NER is just one example; you can incorporate many other advanced queries during this process, so do not limit yourself to this. At the end I also show “Another Use Case” where we actually use the same code to retrieve specific company info from their website.
Why ScrapeGraphAI?
Scrapegraph-ai is an open-source library for AI-powered scraping. Just activate the API keys, and you can scrape thousands of web pages in seconds!
There are quite some cool concepts in this “new” package.
- For reading URLs, it internally uses Playwright which, in my experience, delivers excellent results (you can also pass the HTML if you already have it). Playwright excels at rendering JavaScript-heavy websites, which is crucial for accurate scraping.
- It allows to connect various LLM providers (OpenAI,Ollama,etc.)
Installation (using WSL)
Reference used. I use the ‘uv’ to manage Python dependencies. Here is my installation script:
uv add playwright
playwright install
uv add scrapegraphai
Use openai/gpt-4o-mini for quality baseline
I initially tested this code with gpt-3.5-turbo, but it underperformed, with many articles missing titles or text. When using gpt-4o-mini results were excellent, therefore will use this as baseline for later testing local models.
What about costs (OpenAI)?
This is not a minor issue if you are going to work with a lot of data. My tests, processing about 100 pages, cost $0.21 USD, making the cost per page very low, but nevertheless could become significant for large-scale data projects. That is why in the next article we will investigate doing exactly the same but with local LLMs.
Prompt (example using NER )
prompt = """ This page contains a single news article.
Please extract information based on the given schema.
Use smart and advanced Named Entity Recognition (NER) to find all persons,
organization (companies) and places(locations) mentioned inside
the text article and title.
Ignore all things not related to the main article, exclude :
links to external pages, legal information, advertisement,
cookie information, other stories, social media."""
Main loop
from tqdm import tqdm
results = []
for url in tqdm(urls, desc="Processing URLs"):
smart_scraper_graph = SmartScraperGraph(
prompt=prompt,
source=url,
config=graph_config,
schema=NewsSchema,
)
result = smart_scraper_graph.run()
result['url'] = url
results.append(result)
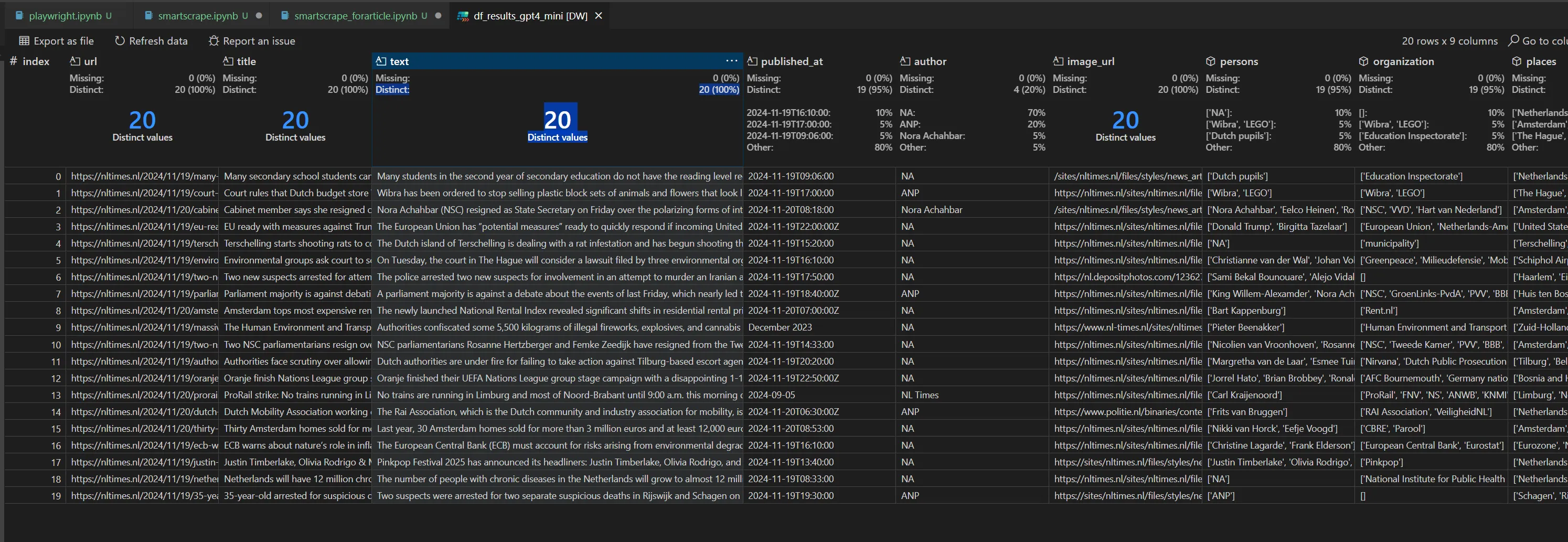
Final result
A very nice extraction:
Practical tips
Use WSL instead of Windows
If you’re using a Windows machine for development, Playwright may not function correctly in Jupyter notebooks due to asynchronous execution issues. So we suggest to use it under WSL.
Warning: This tool has a dependency with Playwright and if you are using windows + Jupiter notebooks then this will not work due to async issues ( tried all tips found, none worked with latest versions). So if you start getting errors, use WSL instead of windows.
Use a json schema for response
This will allow to make sure that the response follows your response schema, this is quite important and there was not a clear documentation about this topic in their docs. Maybe it is just obvious but it was not initially obvious to me. ;)
from pydantic import BaseModel
class NewsSchema(BaseModel):
url: str
title: str
text: str
published_at: str
author: str
image_url: str
persons: list
organization: list
places: list
Pydantic ensures the response adheres to a strict schema, providing reliability and clarity during data processing.
Another use-case: “Extract company information”
The previous code can be easily adapted to a completely different use case, like competitor analysis or simple extract other type of information from a totally different type of website. So based on the previous code, you basically need to redefine the “extraction model” ( result / output json) and the prompt:
from pydantic import BaseModel
class CompanySchema(BaseModel):
name: str
industry: str
employees: str
address: str
contact: str
blog: str
prompt = "You are going to analyze a website to review company information. The page given is the home page of a company. Please extract the information given in the provided schema. Use smart and advanced Named Entitiy Recognition (NER) to find employees ( and/or people working in this company). Try to find the main category using the European industry standard. In contact place any information related to how and who to contact. Try to find if the company has some type of blog or news section."
If you run it for our company (www.syndev.com) you get this impressive result:

Want to know more?
Book a meeting with me via Calendly or contact us!